Speech Detection Recipes
Overview
Speech detection is integrated in the other models to ensure voice insights are only applied to parts of the audio that contain speech. This is provided by either the Speech or the SpeechRT models (currently the SpeechRT model). Here, we will review the speech models on their own and how they can be used for a more granular control in detecting music and voice in audio.
Future iterations of the models will include more detailed human sounds.
Additionally to speech detection, all the input audio is subject to volume level analysis. Depending on the selected sensitivity, very quiet snippets will be marked as silence.
You can fine-tune the volume detection sensitivity by adjusting the volume_threshold parameter (in both, file processing and real time processing case).
Setting it to 0 will not consider any snippet as silence, while setting it to 1 will treat all input as silence.
The first three examples here address the combined use of the Speech model, together with the Arousal model to detect music and high energy segments in audio from vlogs:
- basic analysis of audio files with built-in summarization options - example 1
- custom summarization options for audio file analysis - example 2
- custom speech threshold using the raw output of the model - example 3
If you require speech detection at a real-time frequency (ie. with reduced latency) you may try our SpeechRT model. For the latest advice on which speech model to use, please review the Speech vs SpeechRT section of the Overview.
To see it in action, head to example 4 below.
Pre-requisites
- DeepTone with license key and models
- audio file(s) you want to process
Sample data
You can download this sample audio filewith our CTO talking about OTO for the examples 1-3 below. To better illustrate low latency of the SpeechRT model you can use this file (a woman and a man speaking with some pauses at the beginning, at the end and in between).
Default summaries - Example 1
Remember to add a valid license key before running the example.
In this examples we make use of the summary and transitions level outputs, calculated optionally when processing a file.
The summary output presents us with the fraction of the audio which falls in a particular class. In the case below we are interested in the high arousal part of the speech, ignoring the audio with no speech detected.
In the second part of the example, we also look at the transitions to count how many uninterrupted segments of music we could find in this file.
from deeptone import Deeptone
from deeptone.deeptone import AROUSAL_HIGH, AROUSAL_NO_SPEECH
import time
# Set the required constants
VALID_LICENSE_KEY = None
FILE_TO_PROCESS = None
assert not None in (VALID_LICENSE_KEY, FILE_TO_PROCESS), "Set the required constants"
# Initialise Deeptone
engine = Deeptone(license_key=VALID_LICENSE_KEY)
output = engine.process_file(
filename=FILE_TO_PROCESS,
models=[engine.models.Speech, engine.models.Arousal],
output_period=1024,
channel=0,
use_chunking=True,
include_summary=True,
include_transitions=True,
volume_threshold=0
)
arousal_summary = output["channels"]["0"]["summary"]["arousal"]
high_part = arousal_summary[f"{AROUSAL_HIGH}_fraction"] / (
1 - arousal_summary[f"{AROUSAL_NO_SPEECH}_fraction"]
)
totalTimeAroused = round(high_part * 100, 2)
print(f"You were excited {totalTimeAroused}% of the time you were speaking")
print(
f'You had {len([transition for transition in output["channels"]["0"]["transitions"]["speech"] if transition["result"] == "music"])} music transitions'
)
Custom summaries - Example 2
The built-in summary and transitions output present a useful concept of how to collect high-level information from an audio file. They operate on the most granular level of the output - 64ms in most models. As a result, even very small pauses between speech will be reflected in the output. Depending on your use case you may be targeting a more custom summarization.
In this second example, instead of counting all segments with music, we could count only those longer than 1s. The same logic can be applied in calculating summaries of the audio file - you can always operate on the level of the timeseries and calculate whatever property you need.
from deeptone import Deeptone
from deeptone.deeptone import AROUSAL_HIGH, AROUSAL_NO_SPEECH
import time
# Set the required constants
VALID_LICENSE_KEY = None
FILE_TO_PROCESS = None
assert not None in (VALID_LICENSE_KEY, FILE_TO_PROCESS), "Set the required constants"
# Initialise Deeptone
engine = Deeptone(license_key=VALID_LICENSE_KEY)
output = engine.process_file(
filename=FILE_TO_PROCESS,
models=[engine.models.Speech, engine.models.Arousal],
output_period=1024,
channel=0,
use_chunking=True,
include_summary=True,
include_transitions=True,
volume_threshold=0
)
arousal_summary = output["channels"]["0"]["summary"]["arousal"]
high_part = arousal_summary[f"{AROUSAL_HIGH}_fraction"] / (
1 - arousal_summary[f"{AROUSAL_NO_SPEECH}_fraction"]
)
totalTimeAroused = round(high_part * 100, 2)
print(f"You were excited {totalTimeAroused}% of the time you were speaking")
print(
f'You had {len([transition for transition in output["channels"]["0"]["transitions"]["speech"] if transition["result"] == "music"])} music transitions'
)
# Custom transition count
long_music_transition = 0
for transition in output["channels"]["0"]["transitions"]["speech"]:
if transition["result"] == "music":
music_duration = transition["timestamp_end"] - transition["timestamp_start"]
if music_duration > 1000 and transition["confidence"] > 0.5:
long_music_transition += 1
print(f"You had {long_music_transition} music transitions with duration at least 1s")
Custom speech thresholds - Example 3
DeepTone™ has been designed with ease of use as a primary goal, enabling developers to get to the results as fast as possible.
That's why in the default output, the models always report the class with the higher probability to be correct.
However, in certain situation you may be interested in the probabilities of other classes.
For that purpose, you can request the raw data, by passing in include_raw_values parameter.
Imagine that a piece of audio has voice and music overlapping in some sections. This may lead to certain sections being labelled music even though there is some speech in them too. If you are interested in detecting any speech, even that over music or other overwhelming background noises, you could use the raw values to find segments where speech is not the label with the highest probability, but there is some probability that it is there.
In the example file, the audio has some music and voice segments, as well as pure music. With the default classification, the speech segments amount to 48.7%, or 46.75 seconds of the total file. Visually this looks like the image below:
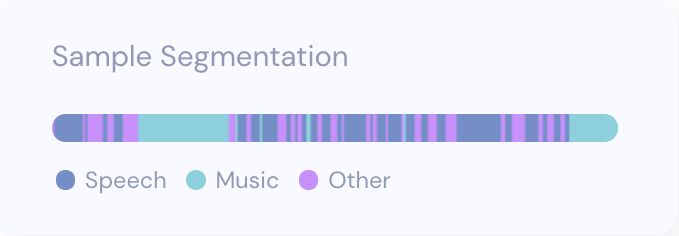
If we are interested in a more speech-sensitive analysis, we can use the raw output of the model and decide to treat anything with probability > 0.1 as speech. This means higher recall on the speech segments, and fewer segments which have both speech and music, being classified as music. With this method, the speech segments amount to 73.04%, or 70.12 seconds of the total audio. If we were to plot the audio file with the more speech-sensitive approach, we can see the longer uninterrupted segments. This approach may make sense for applications where any speech should be detected.
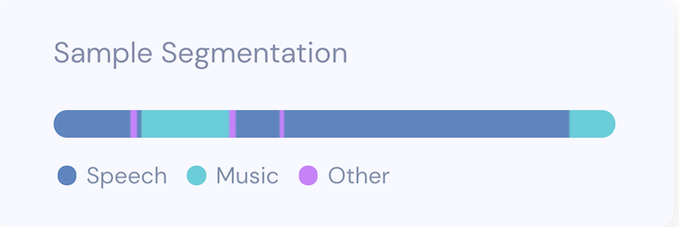
To achieve this result you can use the code below with this audio file.
from deeptone import Deeptone
from deeptone.deeptone import SPEECH_MUSIC, SPEECH_OTHER, SPEECH_SPEECH, SPEECH_SILENCE
# Set the required constants
VALID_LICENSE_KEY = None
FILE_TO_PROCESS = None
assert not None in (VALID_LICENSE_KEY, FILE_TO_PROCESS), "Set the required constants"
# Initialise Deeptone
engine = Deeptone(license_key=VALID_LICENSE_KEY)
output = engine.process_file(
filename=FILE_TO_PROCESS,
models=[engine.models.Speech],
output_period=1024,
channel=0,
use_chunking=True,
include_raw_values=True,
include_transitions=True,
volume_threshold=0
)
# Set a custom speech threshold for the probability
custom_speech_threshold = 0.1
raw_speech_results = {"speech": 0, "non_speech": 0}
speech_results = {"speech": 0, "non_speech": 0}
for time_step in output["channels"]["0"]["time_series"]:
speech_result_raw = time_step["raw"]["speech"][SPEECH_SPEECH]
speech_result = time_step["results"]["speech"]["result"]
if speech_result_raw > custom_speech_threshold:
raw_speech_results["speech"] += 1
else:
raw_speech_results["non_speech"] += 1
if speech_result == "speech":
speech_results["speech"] += 1
else:
speech_results["non_speech"] += 1
minutes = int(time_step['timestamp']/60000)
seconds = int(time_step['timestamp']/1000 - minutes*60)
print(f"Time: {minutes}min {seconds}s\tResult: {time_step['results']['speech']['result']},\tRaw result speech: {time_step['raw']['speech']['speech']}")
speech_fraction_raw = round(100 * raw_speech_results["speech"] / (raw_speech_results["speech"] + raw_speech_results["non_speech"]), 2)
speech_fraction = round(100 * speech_results["speech"] / (speech_results["speech"] + speech_results["non_speech"]), 2)
print(f"Raw speech fraction: {speech_fraction_raw}% = {round(96*speech_fraction_raw/100, 2)} sec")
print(f"Speech fraction: {speech_fraction}% = {round(96*speech_fraction/100, 2)} sec")
Speech detection with reduced latency - Example 4
Some applications may require speech detection with reduced latency for quick recognition whether someone is speaking or not. Our default Speech model is able to distinguish speech and music from other sounds but it may not be suitable for the low latency scenarios. The SpeechRT model, however, can detect speech much more rapidly than the default Speech model and can therefore be used in such cases.
In the example shown below we will use the transitions feature to find the transition points in the audio where one class
changes to another. Later, we will load those labels (together with the waveform) into Audacity
to visualise where the model detected speech.
import numpy as np
from deeptone import Deeptone
# Set the required constants
VALID_LICENSE_KEY = None
FILE_TO_PROCESS = None
OUTPUT_LABELS_FILE = None # path to a TXT file where the labels will be saved
assert not None in (VALID_LICENSE_KEY, FILE_TO_PROCESS, OUTPUT_LABELS_FILE), "Set the required constants"
# Initialise Deeptone
engine = Deeptone(license_key=VALID_LICENSE_KEY)
output = engine.process_file(
filename=FILE_TO_PROCESS,
models=[engine.models.SpeechRT],
output_period=64,
channel=0,
use_chunking=False,
include_raw_values=False,
include_transitions=True,
volume_threshold=0
)
speech_rt_transitions = output["channels"]["0"]["transitions"]["speech-rt"]
with open(OUTPUT_LABELS_FILE, "w") as f:
for time_step in speech_rt_transitions:
f.write(f"{time_step['timestamp_start']/1000}\t{time_step['timestamp_end']/1000}\t{time_step['result']}\n")
After running the script, you can import both, the audio file and the labels file, into a new project in Audacity (File -> Import -> Audio, File -> Import -> Labels). The first few seconds should look like this:
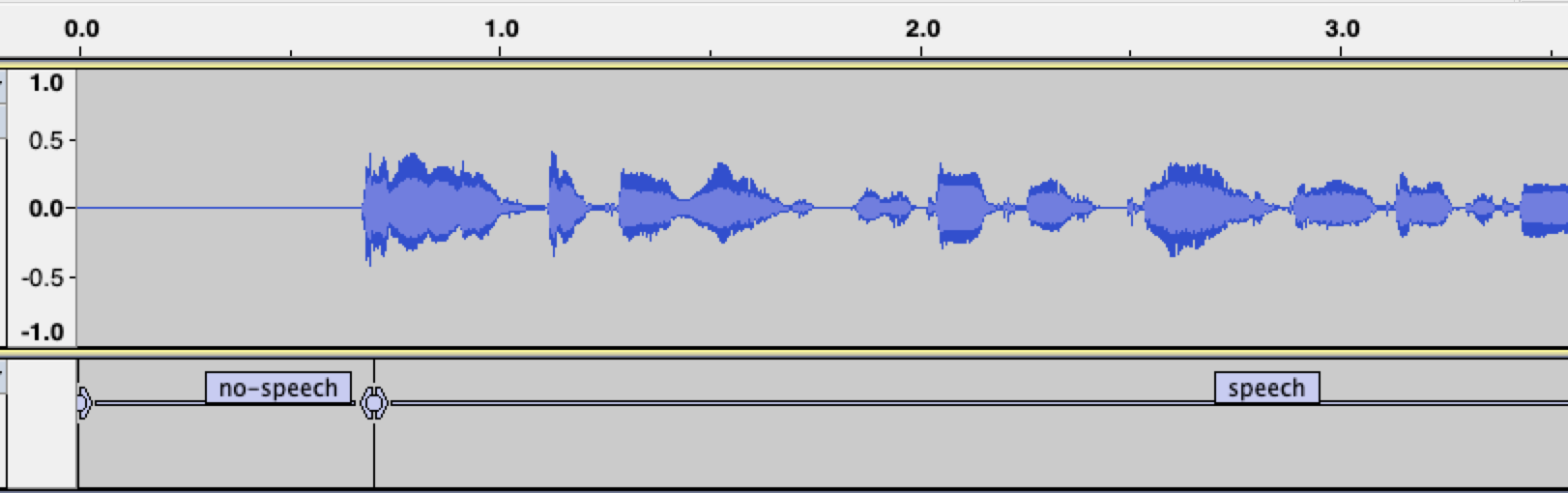
As can be seen around 0.7s, the SpeechRT model gets activated within ~50ms from the point when the first speaker starts speaking.